学习大数据的过程中,避免不了,需要有大数据的环境,没有,我们就需要自己动手搭建。以下内容是在安装好linux虚拟机的基础上部署Hadoop,并搭建Hadoop分布式环境。一般情况下安装好虚拟机后,需要配置网络静态IP,并设置网卡自动启动,虚拟机才能连接网络。
具体设置如下:
Linux设置静态IP步骤如下
1.先输入命令【route -n】查看路由地址并记下
如果命令route提示“bash: route: command not found”
使用yum命令安装,仅限Center OS
yum install net-tools
2.然后找到网卡配置文件编辑【cd /etc/sysconfig/network-scripts/】
在文件中添加一下配置
IPADDR=192.168.50.130 #希望的ip地址
NETMASK=255.255.255.0 #默认
GATEWAY=192.168.50.2 #之前记下的网关地址
DNS1=192.168.50.2 #和网关一样
然后把以下属性求改为如下
ONBOOT=”yes” # 开机启动
BOOTPROTO=”static” #设置为静态的
3.service network restart
Hadoop安装环境配置如下
一、系统主机名称修改
1.使用sudo vi /etc/sysconfig/network 打开配置文件,根据实际情况设置该服务器的机器名,新机器名在重启后生效
NETWORKING=yes
NETWORKING_IPV6=no
HOSTNAME=master
2.设置Host映射文件
设置IP地址与机器名的映射,设置信息如下:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.113.129 master
192.168.113.130 node01
192.168.113.131 node02
192.168.113.132 node03
3.重启机器 reboot
4.测试主机名称是否修改成功
二、下载对应系统版本的JDK安装包
具体下载从Oracle官网下载相应的版本。
下载地址:https://www.oracle.com/technetwork/java/javase/archive-139210.html
三、安装Java JDK
1.查看linux下已经安装的JDKrpm -qa | grep java
结果:
python-javapackages-3.4.1-11.el7.noarch
java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64
tzdata-java-2018c-1.el7.noarch
java-1.7.0-openjdk-1.7.0.171-2.6.13.2.el7.x86_64
java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
javapackages-tools-3.4.1-11.el7.noarch
java-1.7.0-openjdk-headless-1.7.0.171-2.6.13.2.el7.x86_64
2.卸载存在的JDKyum remove *openjdk*
3.上传下载的JDK安装包rz -f
将JDK安装包上传到 /usr/local/java 目录下(该目录一般为JDK的标准安装目录,也可使用whereis java 或 find -name java 查看本地的java目录)
4.解压上传的JDK安装包tar -zxvf jdk-8u221-linux-x64.tar.gz
5.配置环境变量vim /etc/profile
6.在最前面加上 (JAVA_HOME的值为jdk的解压目录)
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
7.执行profile文件,使环境变量生效source /etc/profile
8.验证JDK是否安装成功java -version
出现如下信息则安装成功:
java version “1.8.0_221”
Java(TM) SE Runtime Environment (build 1.8.0_221-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode)
四、关闭系统防火墙
在Hadoop安装过程中需要关闭防火墙和SElinux,否则会出现异常
1.CentOS6关闭防火墙使用以下命令,
//临时关闭
service iptables stop
//禁止开机启动
chkconfig iptables off
CentOS7中若使用同样的命令会报错,
stop iptables.service
Failed to stop iptables.service: Unit iptables.service not loaded.
这是因为CentOS7版本后防火墙默认使用firewalld,因此在CentOS7中关闭防火墙使用以下命令,
//临时关闭
systemctl stop firewalld
//禁止开机启动
systemctl disable firewalld
结果如下:
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
当然,如果安装了iptables-service,也可以使用下面的命令,
yum install -y iptables-services
//关闭防火墙
service iptables stop
Redirecting to /bin/systemctl stop iptables.service
//检查防火墙状态
service iptables status
Redirecting to /bin/systemctl status iptables.service
iptables.service - IPv4 firewall with iptables
Loaded: loaded (/usr/lib/systemd/system/iptables.service; disabled; vendor preset: disabled)
Active: inactive (dead)
2.关闭SElinux使用getenforce命令查看是否关闭修改/etc/selinux/config 文件将SELINUX=enforcing改为SELINUX=disabled,执行该命令后重启机器生效reboot
五、更新OpenSSL
CentOS自带的OpenSSL存在bug,使用如下命令进行更新:yum update openssl
六、克隆配置好网络和安装好JDK的虚拟机(为Hadoop集群做准备)
克隆三个节点的虚拟机 node01、node02、node03 然后分别开启虚拟机,配置各个虚拟机的静态IP
七、配置SSH免密登录(直接看第八步)
1.使用sudo vi /etc/ssh/sshd_config,打开sshd_config配置文件,开放三个配置,添加到文件内容首部,如下所示:
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
2.重启SSHD服务sudo service sshd restart
3.使用如下命令生成 私钥和公钥ssh-keygen -t rsa
4.cd ~/.ssh 目录会发现生成了 id_rsa 和 id_rsa.pub 两个秘钥。其中.pub 为公钥。
5.把公钥命名为authorized_keys,使用命令如下:cp id_rsa.pub authorized_keys
6.使用如下设置authorized_keys读写权限sudo chmod 400 authorized_keys
7.测试免密登录 ssh master,此处登录到本机
8.配置master免密码登录各个节点
将master节点上的authoized_keys远程传输到node01和node02、node03 的~/.ssh/目录下
使用一下命令将生成的公钥 authorized_keys 分发到每个节点的 .ssh目录
注意:此处会发生.ssh 目录不存在的情况,如果提示.ssh目录不存在,则执行 ssh localhost(主机名) 命令即可!
原因: .ssh 是记录密码信息的文件夹,如果没有登录过root的话,就没有 .ssh 文件夹,因此登录 localhost ,并输入密码就会生成了。scp ~/.ssh/authorized_keys root@node01:~/.ssh/scp ~/.ssh/authorized_keys root@node02:~/.ssh/scp ~/.ssh/authorized_keys root@node03:~/.ssh/
9.测试免密登录
输入ssh node01即可登录到node01节点,输入exit退出当前登录
设置SSH免密钥(最新)每台机器间都要设置免密登录
1.关于ssh免密码的设置,要求每两台主机之间设置免密码,自己的主机与自己的主机之间也要求设置免密码。 这项操作可以在admin用户下执行,执行完毕公钥在~/.ssh/id_rsa.pub
[admin@node00 ~]# ssh-keygen -t rsa
[admin@node00 ~]# ssh-copy-id node01
[admin@node00 ~]# ssh-copy-id node02
[admin@node00 ~]# ssh-copy-id node03
2.node1与node2为namenode节点要相互免秘钥 HDFS的HA
[admin@node01 ~]# ssh-keygen -t rsa
[admin@node01 ~]# ssh-copy-id node00
[admin@node01 ~]# ssh-copy-id node02
[admin@node01 ~]# ssh-copy-id node03
3.node2与node3为yarn节点要相互免秘钥 YARN的HA
[admin@node02 ~]# ssh-keygen -t rsa
[admin@node02 ~]# ssh-copy-id node00
[admin@node02 ~]# ssh-copy-id node01
[admin@node02 ~]# ssh-copy-id node03
…
本机与本机之间设置免密登录
将本机生成的id_rsa.pub追加到authorized_keys中cat id_rsa.pub >> authorized_keys
八、添加用户账号
在所有的主机下均建立一个账号admin用来运行hadoop ,并将其添加至sudoers中
[root@node00 ~]# useradd admin 添加用户通过手动输入修改密码
[root@node00 ~]# passwd admin 更改用户 admin 的密码
123456 passwd: 所有的身份验证令牌已经成功更新。
设置admin用户具有root权限 修改 /etc/sudoers 文件,找到下面一行,在root下面添加一行,如下所示:1
2
3
4[root@node00 ~]# vi /etc/sudoers
//# Allow root to run any commands anywhere
root ALL=(ALL) ALL
admin ALL=(ALL) ALL
修改完毕 :wq! 保存退出,现在可以用admin帐号登录,然后用命令 su - ,切换用户即可获得root权限进行操作。
九、/opt目录下创建文件夹
1)在root用户下创建module、software文件夹1
2[root@node00 opt]# mkdir module
[root@node00 opt]# mkdir software
2)修改module、software文件夹的所有者1
2[root@node00 opt]# chown admin:admin module
[root@node00 opt]# chown admin:admin software
3)查看module、software文件夹的所有者1
2
3
4[root@node00 opt]# ll
total 0
drwxr-xr-x. 5 admin admin 64 May 27 00:24 module
drwxr-xr-x. 2 admin admin 267 May 26 11:56 software
十、Hadoop官网上面下载Hadoop安装包,并安装。
1.下载地址,此处下载的 hadoop-2.9.2.tar.gz 版本
http://hadoop.apache.org/releases.html
2.上传到服务器/opt/modulem目录,并解压Hadoop安装包
执行如下命令解压:tar -zxvf hadoop-2.9.2.tar.gz
解压完成后可以看见目录如下:1
2
3
4[root@node00 module]# ll
总用量 357860
drwxr-xr-x 9 501 dialout 149 11月 13 2018 hadoop-2.9.2
-rw-r--r-- 1 root root 366447449 10月 31 11:46 hadoop-2.9.2.tar.gz
十一、配置hadoop集群
集群部署规划
| 节点名称 | NN1 | NN2 | DN | RN | NM |
|---|---|---|---|---|---|
| node00 | NameNode | DataNode | NodeManager | ||
| node01 | SecondaryNameNode | DataNode | ResourceManager | NodeManager | |
| node02 | DataNode | NodeManager | |||
| node03 | DataNode | NodeManager |
进入 hadoop-2.9.2/etc/hadoop 目录按照如下顺序配置各个配置文件。
(注意:配置文件在hadoop2.7.6/etc/hadoop/下)
- 修改core-site.xml
- 修改hadoop-env.sh
- 修改hdfs-site.xml
- 修改slaves
- 修改mapred-env.sh
- 修改mapred-site.xml
- 修改yarn-env.sh
- 修改yarn-site.xml
- 分发hadoop到节点
- 配置环境变量
下面是每个步骤的详细说明。
1.修改core-site.xml
[root@node00 hadoop]$ vi core-site.xml1
2
3
4
5
6
7
8
9
10
11
12<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node00:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.9.2/data/full/tmp</value>
</property>
</configuration>
2.修改hadoop-env.sh1
2[root@node00 hadoop]$ vi hadoop-env.sh
修改 export JAVA_HOME=/usr/local/java/jdk1.8.0_221
3.修改hdfs-site.xml1
2
3
4
5
6
7
8
9
10
11
12
13[admin@node00 hadoop]$ vi hdfs-site.xml
<configuration>
<!-- 设置dfs副本数,不设置默认是3个,此处我设置为3个 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 设置secondname的端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
</configuration>
4.修改slaves1
2
3
4
5[admin@node00 hadoop]$ vi slaves
node00
node01
node02
node03
5.修改mapred-env.sh1
2[admin@node00 hadoop]$ vi mapred-env.sh
修改 export JAVA_HOME=/usr/local/java/jdk1.8.0_221
6.修改mapred-site.xml1
2
3
4
5
6
7
8
9[admin@node00 hadoop]# cp mapred-site.xml.template mapred-site.xml
[admin@node00 hadoop]$ vi mapred-site.xml
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
7.修改yarn-env.sh1
2[admin@node00 hadoop]$ vi yarn-env.sh
修改 export JAVA_HOME=/usr/local/java/jdk1.8.0_221
8.修改yarn-site.xml1
2
3
4
5
6
7
8
9
10
11
12
13[admin@node00 hadoop]$ vi yarn-site.xml
<configuration>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
</configuration>
9.将配置好的hadoop分发到每个节点1
2
3[root@node00 module]# scp -r hadoop-2.9.2 node01:/opt/module/
[root@node00 module]# scp -r hadoop-2.9.2 node02:/opt/module/
[root@node00 module]# scp -r hadoop-2.9.2 node03:/opt/module/
10.配置环境变量1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26[root@node00 ~]$ sudo vi /etc/profile
末尾追加
export HADOOP_HOME=/opt/module/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
编译生效 source /etc/profile
测试 hadoop命令,出现以下结果说明环境变量配置成功
[root@node00 module]# hadoop
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar <jar> run a jar file
note: please use "yarn jar" to launch
YARN applications, not this command.
checknative [-a|-h] check native hadoop and compression libraries availability
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
Hadoop jar and the required libraries
credential interact with credential providers
daemonlog get/set the log level for each daemon
trace view and modify Hadoop tracing settings
Most commands print help when invoked w/o parameters.
11.将配置好的环境变量分发到各个节点,并逐个编译生效 source /etc/profile1
2
3[root@node00 module]# scp /etc/profile node01:/etc/profile
[root@node00 module]# scp /etc/profile node02:/etc/profile
[root@node00 module]# scp /etc/profile node03:/etc/profile
十二、启动验证集群
1.启动集群,如果集群是第一次启动,需要格式化namenode1
2
3[root@node00 hadoop-2.9.2]# hdfs namenode -format
出现如下信息说明成功:
19/10/31 18:02:23 INFO common.Storage: Storage directory /opt/module/hadoop-2.9.2/data/full/tmp/dfs/name has been successfully formatted.
2.启动Hdfs1
2
3
4
5
6
7[root@node00 hadoop-2.9.2]# start-dfs.sh
Starting namenodes on [node00]
node00: starting namenode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-root-namenode-node00.out
node02: starting datanode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-root-datanode-node02.out
node00: starting datanode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-root-datanode-node00.out
node01: starting datanode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-root-datanode-node01.out
node03: starting datanode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-root-datanode-node03.out
注:
我第一次启动的时候,发现每个节点的DateNode都没有启动,经查阅资料,多次格式化namenode导致的namenode与datanode之间的不一致(多次格式化,版本不一致)。导致启动失败。
解决:把Hadoop下的log和tmp文件夹删掉、Hadoopdata里面文件删除(没有Hadoopdata文件,则将Hadoop下的dfs下的data里面文件删掉)
过程:
先关闭dfs:./sbin/stop-dfs.sh
删除掉Hadoop下的data里面的东西
删除Hadoop下的logs和temp文件夹
重新进行namenode格式化:hdfs namenode format
重启集群:./sbin/start-dfs.sh
查看进程:jps
1
2
3
4
5
6
7
8
9$ jps
8115 Jps
7775 DataNode
7681 NameNode
7933 SecondaryNameNode
3.启动Yarn:
注意:Namenode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn。
本次安装Namenode在node00机器上,ResourceManger 配置在 node01机器上。因此需要到node01机器上启动Yarn1
2
3
4
5
6
7[root@node01 data]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-root-resourcemanager-node01.out
node03: starting nodemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-root-nodemanager-node03.out
node00: starting nodemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-root-nodemanager-node00.out
node02: starting nodemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-root-nodemanager-node02.out
node01: starting nodemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-root-nodemanager-node01.out
4.jps查看各个节点的进程
node001
2
3
4
5[root@node00 hadoop-2.9.2]# jps
11872 NodeManager
12002 Jps
11462 NameNode
11599 DataNode
node011
2
3
4
5
6[root@node01 data]# jps
9554 NodeManager
9220 DataNode
9895 Jps
9450 ResourceManager
9326 SecondaryNameNode
node021
2
3
4[root@node02 data]# jps
8832 NodeManager
8970 Jps
8686 DataNode
node031
2
3
4[root@node03 logs]# jps
8946 Jps
8653 DataNode
8798 NodeManager
至此,所有节点都启动成功!
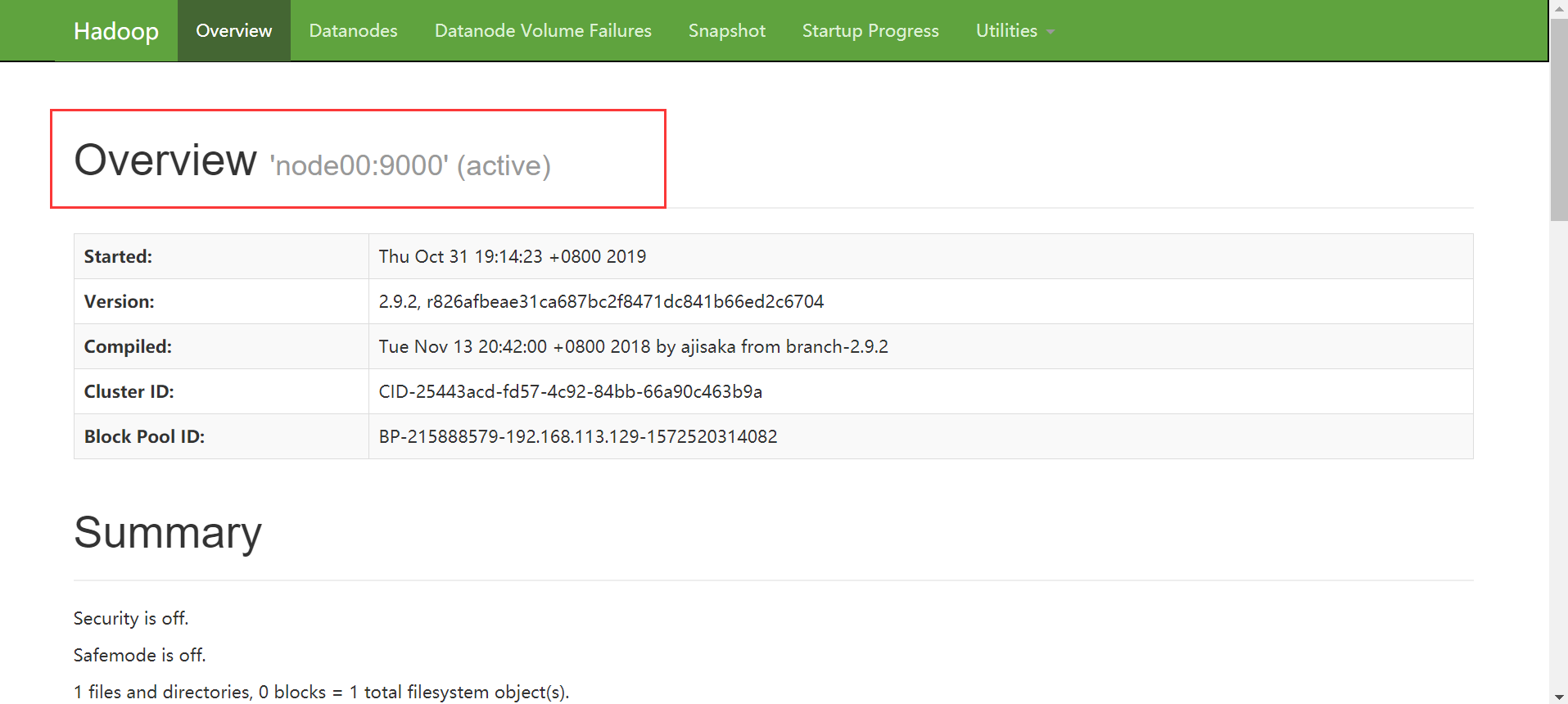
5.登录Web查看网页
访问地址:http://192.168.113.129:50070/